Si has seguido Twitter estos días, seguro que habrás visto la que se ha liado con el hilo de Manuel Bartual. Si no lo has visto, te recomiendo que le eches un ojo
a partir de este primer tweet. Si bien la historia no es nada especial, la forma de hacerlo sí que ha sido "revolucionaria". Manuel nos ha narrado en primera persona y "en directo" sus "vacaciones", teniendo enganchados a al menos 400.000 seguidores (que se dice pronto), todos ellos pendientes de saber qué iba a pasar a continuación.
Sin meterme en la parte literaria, me ha apetecido echarle un ojo a los tweets y ver si detectaba algo interesante. El análisis que os traigo no es exhaustivo y puede tener algún error, ya que lo he hecho en un par de ratos tontos que me aburría. Tampoco busco probar ningua hipótesis, es un mero análisis exploratorio.
Estáis advertidos.
- El primer paso: Obtener los mensajes.
Manuel ha estado publicando desde el día 21 hasta el día 27 de Agosto. Obviamente esto implica que recuperar los mensajes a mano es inviable.
La primera idea que me vino a la cabeza fue cargar la página completa del autor en Twitter y mirar si el HTML era "parseable" (se podían extraer los mensajes) de forma fácil. No obstante, el código es demasiado enredado, mucho JavaScript y demás para poder tener los datos limpios.
Como digo, me parecía demasiado enrevesado extraer los mensajes del código, así que me puse a buscar alguna librería por ahí que te permitiera pedir los mensajes a la API de Twitter. Tuve suerte y relativamente rápido encontré
esta librería que precisamente te permite conectar con Twitter desde Python. Tuve que hacer un par de cambios al ejemplo que venía en su web, ya que Twitter te limita a obtener los mensajes de 200 en 200, pero nada complicado. Dejo
aquí el código fuente por si alguien lo quiere reutilizar.
 |
| Último mensaje (en bruto) de Manuel, con el texto "¿Hola?" |
Ya tenía los mensajes. Decidí obtenerlos la mañana del 27 a las 13.06h hora de Madrid. Es decir, que me guardé sólo desde el primero al que termina en "
¿hola?", pues considero que es el fin del relato. Si en estos días hay más tuits relevantes, puede que repita el análisis, pero de momento me vale hasta ahí. Menciono la hora a la que he obtenidos los mensajes, ya que al ser datos dinámicos, los "Me gusta"/"Favoritos" o "Retweets" son los que he obtenido a dicha hora, probablemente ahora sean más.
En total extraje 374 mensajes.
- El segundo paso: Mirar los metadatos.
Twitter nos ofrece bastante información más allá del texto. Entre otras cosas, nos dice la fecha exacta de publicación de los mensajes, el número de favoritos que tienen, los RTs que se han hecho hasta ese momento, el idioma, etcétera. Antes de mirar los textos en sí, podemos hacer un repaso de estos metadatos, además como tenemos la fecha de cada mensaje, podemos estudiar series temporales.
Lo primero que podemos mirar es cuándo se publicaron mensajes:
En esta primera gráfica vemos cómo empiezan los tweets el día 21 a última hora y cómo la mayoría se concentran a última hora del 25 y a lo largo del día 26.
Si los agrupamos por días vemos que, efectivamente, la gran mayoría se concentran en el día 26 con alrededor de un tercio de mensajes del total:
El dato atípico de la izquierda con un número de Favoritos y RT tan alto se corresponde con el primer tweet del hilo, que es el que está destacado en su perfil y que probablemente sea el que más gente se ha leído, compartido, gustado y guardado.
Es curioso ver como los Favoritos superan siempre a los RTs, lo que implica que en este caso se prima el "gustar" y "guardar", frente al "compartir".
Parece también haber algunos tweets concretos que destacan sobre el resto de la tendencia y que además coinciden con ser el último o el primero del día, como si la gente dijera "hoy has hecho un buen trabajo" o "me alegro de que vuelvas".
Se puede ver también como a lo largo de los días la popularidad va subiendo, siendo los mensajes del día 26 los más populares en ambas categorías.
- El tercer paso: mirar el contenido de los mensajes
Una vez analizados los metadatos, podemos empezar a mirar por encima los datos en sí.
Para empezar podemos comparar la longitud de los mensajes, tanto en caracteres como en palabras:
Estos datos son bastante uniformes, pero se ve una ligera tendencia hacia el 26 y 27 donde los tweets empiezan a tener menos caracteres y sin embargo un número parecido de palabras (o algo inferior al resto de días).
Esto podría deberse al ritmo que se marca en esos tweets, ya que Manuel está intentando crear tensión: los mensajes o contienen menos información, o son muchos y de frases cortas para darle más velocidad y emoción al texto, lo que se reflejaría en su popularidad.
Esto obviamente lo deduzco no sólo de la gráfica superior (en la que no se aprecia tanto) si no conociendo el contenido de los textos. Vamos, que quiero ver la correlación más que realmente verla en estos datos. Pero para el análisis, de momento encaja como hipótesis.
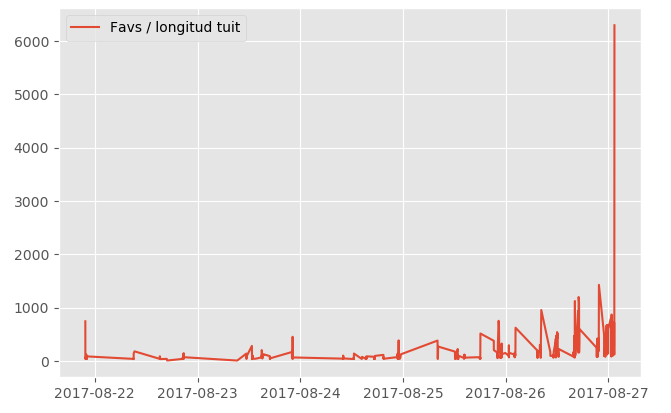
Por un lado hemos visto el número de caracteres y por otro el número de favoritos, ¿qué pasaría si sacamos el número de favoritos con respecto a la longitud del mensaje? Pues que obtenemos esta gráfica:
Ahora se ve más clara esa hipótesis que antes planteábamos: los últimos tweets del hilo acumulan una gran popularidad con respecto a la longitud de estos. Sobre todo el último, que con sólo una palabra acumula más de 40K favoritos.
Por otra parte, podemos analizar las palabras más utilizadas. Para ello he utilizado la herramienta
NLKT que permite realizar procesamiento del lenguaje natural (en este caso el español) desde Python.
Los 374 mensajes están formados por 6.024 palabras, y si quitamos las repeticiones obtenemos 1.260. Quitando las palabras "irrelevantes" (stopwords en inglés), que corresponderían a conjunciones, pronombres, preposiciones..., nos quedan 1121 palabras. Si comprobamos cual es su frecuencia obtenemos el siguiente ranking:
Parece que la "habitación" y el "hotel" eran clave :)
Aunque todos sabemos que el protagonista fue el "bollo", aunque sólo aparezca dos veces, una en singular y otra en plural.
Por otra parte, podemos mostrar esta misma información, pero de forma más resultona, con una nube de palabras. En estos gráficos el tamaño de la palabra es directamente proporcional al número de apariciones: cuantas más veces aparezca una palabra en el texto, más grande es la palabra en la imagen. Para este caso he usado
esta otra librería:
- En definitiva:
Manuel ha hecho un gran trabajo, ha sabido llamar la atención aprovechando
un medio que muchos consideran muerto, pero a pesar de todo ha conseguido destacar y mantenernos atentos a sus mensajes.
Espero que os haya parecido curioso el análisis, si alguien quiere algún detalle más o quiere los datos en bruto, podéis dejarme un comentario o
contactarme por Twitter.
¿Y qué saco yo de todo esto? Pues:
- He aprendido a obtener los mensajes de alguien en Twitter.
- He repasado algún detalle para presentar las gráficas.
- He tocado un mínimo de NLKT para procesar los textos.
- Y he aprendido a dibujar nubes de palabras chulas.
Y todo en un día. No está mal, como dice Manuel: